hadoop相关介绍
本文共 746 字,大约阅读时间需要 2 分钟。
一.简介
大数据:指无法在一定时间范围内用常规软件进行捕捉,管理和处理的数据集合,需要新处理模式才能具有更强的决策力,洞察发现力,和流程优化的能力的海量、高增长率和多样化的信息资产。
主要解决海量数据的存储,海量数据的分析计算:TB,PB,EB
特点:大量(volume),高速(velocity),多样(variety),低价值密度(value), 4v
二.组织架构
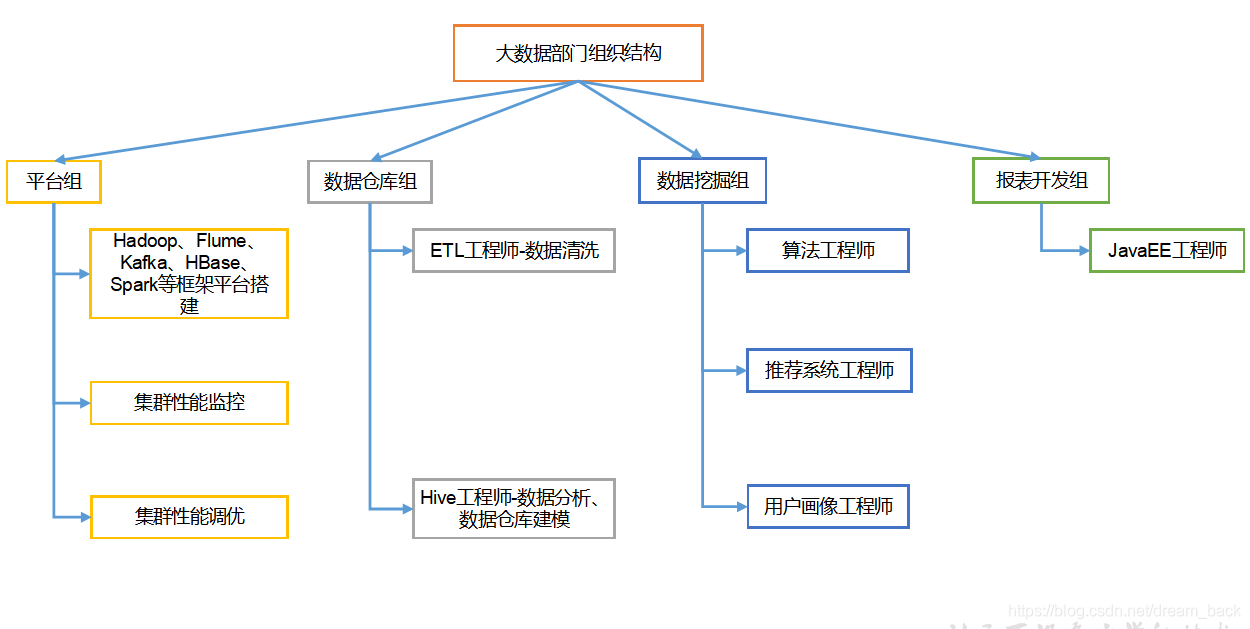
三.hadoop优势
1.高可靠性:底层维护多个数据副本
2.高扩展性:在集群间分配任务,可方便扩展,不用停掉已开启的服务器 3.高效性:并行工作,MapReduce 4.高容错性:自动将失败的任务从新分配四.hadoop组成
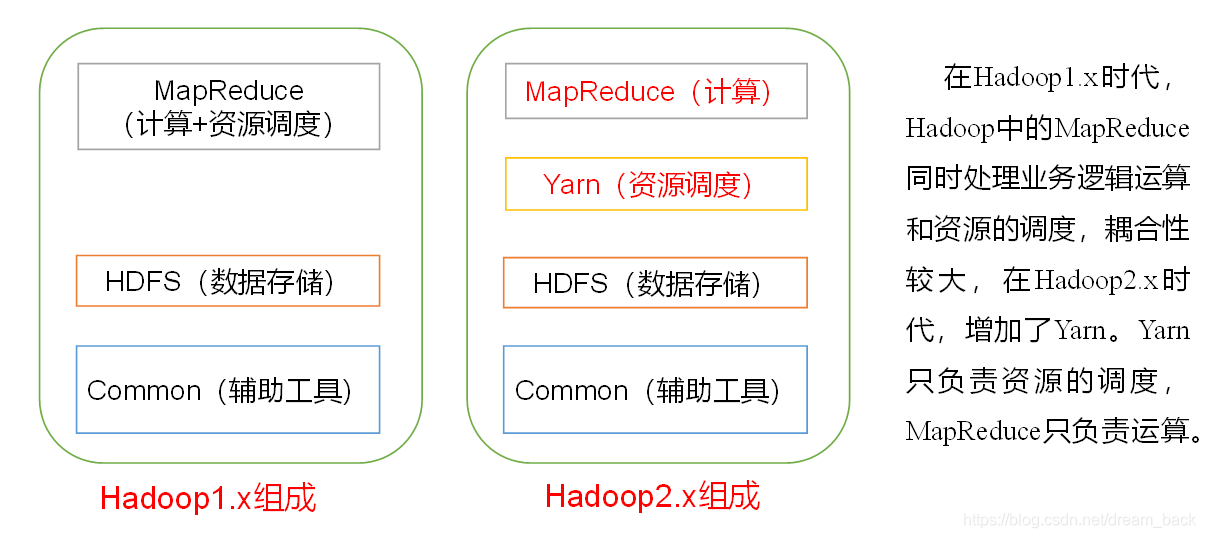
- NameNode: 存储文件的元数据,如目录,文件名,文件属性
- DataNode:文件数据,块数据的校验和
- Secondary NameNode(2nn)
yarn:
-
Resource Manager(RM)
1.处理客户端请求 2.监控Node Manage 3.启动或监控ApplicationMaster 4.资源分配和调度 -
Node Manager(NM)
1.管理单个节点的资源 2.处理来自Resource Manager的命令 3.处理来自applicantMaster的命令 -
ApplicationMaster(AM)
1.负责数据的切分 2.为应用程序申请资源并分配给内部的任务 3.任务的监控与容错 -
Container
是yarn中资源的抽象, 封装了某个节点的多维度资源,如内存,cpu,磁盘,网络等
MapReduce
- Map:并行处理输入数据
- Reduce:对map结果进行汇总
五.大数据生态体系:
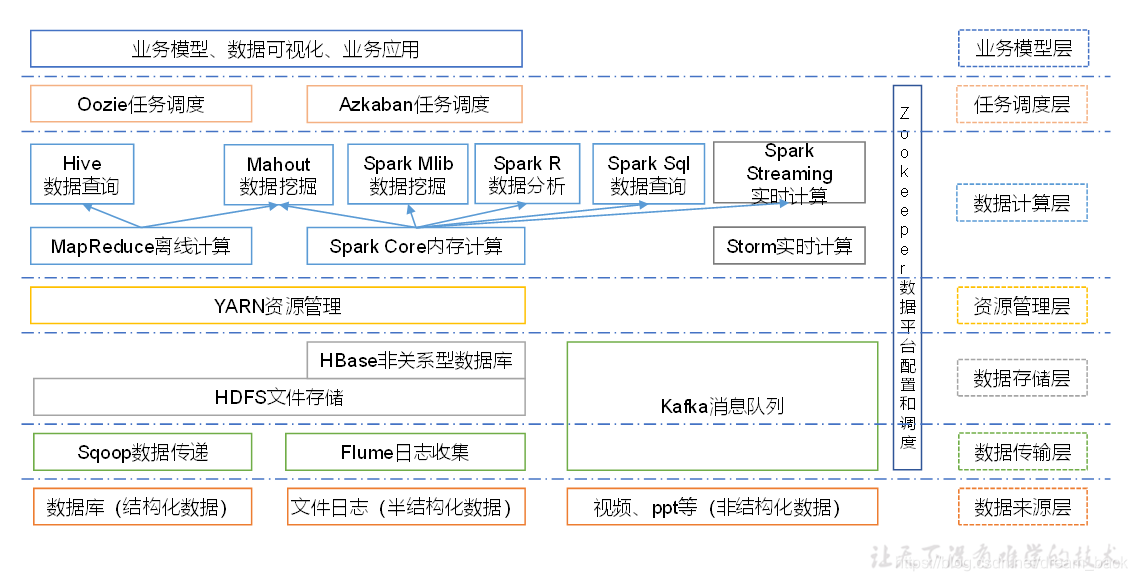
六.推荐系统框架
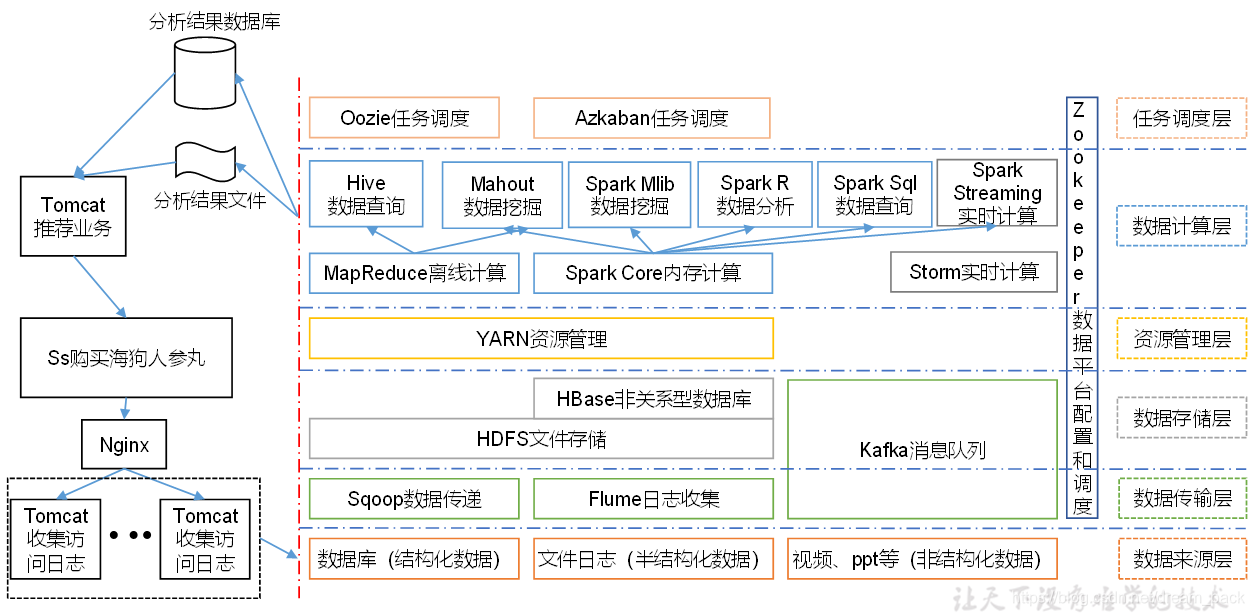
转载地址:http://nwjmf.baihongyu.com/
你可能感兴趣的文章
Linux下Tomcat重新启动
查看>>
使用HttpClient请求另一个项目接口获取内容
查看>>
HttpClient get和HttpClient Post请求的方式获取服务器的返回数据
查看>>
net.sf.json Maven依赖配置
查看>>
Could not initialize class net.sf.json.JsonConfig错误解决
查看>>
Java编程思想重点笔记(Java开发必看)
查看>>
eclipse 创建maven 项目 动态web工程完整示例
查看>>
前端JSP与Spring MVC交互实用例子
查看>>
使用maven一步一步构建spring mvc项目
查看>>
hadoop map reduce 阶段笔记
查看>>
java jackcess 操作 access
查看>>
Git问题Everything up-to-date解决
查看>>
Hadoop HDFS文件操作的Java代码
查看>>
Hadoop学习笔记—3.Hadoop RPC机制的使用
查看>>
Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
查看>>
JTS Geometry关系判断和分析
查看>>
GIS基本概念
查看>>
Java文件操作①——XML文件的读取
查看>>
java学习总结之文件操作--ByteArrayOutputStream的用法
查看>>
Java生成和操作Excel文件
查看>>